Erez Katz, Lucena Research CEO and Co-founder
Using Time Series Data and Neural Networks To Forecast Stock Prices
Through our research at Lucena, we know it’s important to configure deep net infrastructure to accommodate time series data as a trend formation vs. a single point-in-time. There is a vast difference in how we as humans make decisions versus machine learning.
Some decisions rely on a static state (image classification, for example). When we feed an image to a network, it mainly relies on the final state. How the image was drawn or how the picture was formed is not relevant to identifying whether the image contains a cat or a dog.
Static vs. Time Series Data
In contrast, forecasting or predicting an outcome relies on some form of historical context. For example, the autocomplete function on our smartphones is a function of memorizing the previous sequence of letters in a word or the previous sequence of words in a sentence. A sentence that starts with “The sky is____.” would predict with high confidence the next word to be “blue”. But if we only gave the deep network the last word “is,” it would have no relevant information based on which to discern what comes next.
The very same concept applies to stock price prediction data. A traditional artificial neural network may learn to forecast the price of a stock based on several factors:
- Daily Volume
- Price to Earnings Ratio (PE)
- Analyst Recommendations Consensus
While the future price of the stock may heavily depend on these factors, their static values at a point-in-time only tell part of the story. A much richer approach to forecasting a stock price would be to determine how the trend of the above factors formed over time.
Test Using Cross Validation
In other words, let the network try a bunch of timeframes and determine which one works best during a cross validation period. However, the more parameters you add to the grid search, the more susceptible you are to overfitting. Not to mention a trend’s time frame is not necessarily a constant. In some cases, a trend of 21 days is more predictive while in other cases 63 days maybe more suitable.
RNN (Recurrent Neural Network) is a deep neural network designed specifically to tackle this kind of shortcoming. It is able to determine on the fly what type of historical information should be considered or discarded for a high probability classification.
What is a Recurrent Neural Network (RNN)?
A Recurrent Neural Network (RNN) is a deep learning algorithm that operates on sequences (like sequences of characters). At every step, it takes a snapshot before it tries to determine what’s next. In other words, it operates on trend representations via matrixes of historical states.
RNNs have some form of internal memory, so it remembers what it saw previously. In contrast to the fully connected neural nets and convolutional neural nets (which are feed-forward through which a layer of neurons is used as input adjacent and subsequent layer in the hierarchy). RNNs can use the output of a neuron as an input to the very same neuron.

A is the class that determines what information to preserve and what to discard and h(t) is the output neuron which feeds back into the network. Credit: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
The above diagram can be greatly simplified by unfolding (unrolling) the recurrent instances as follows:
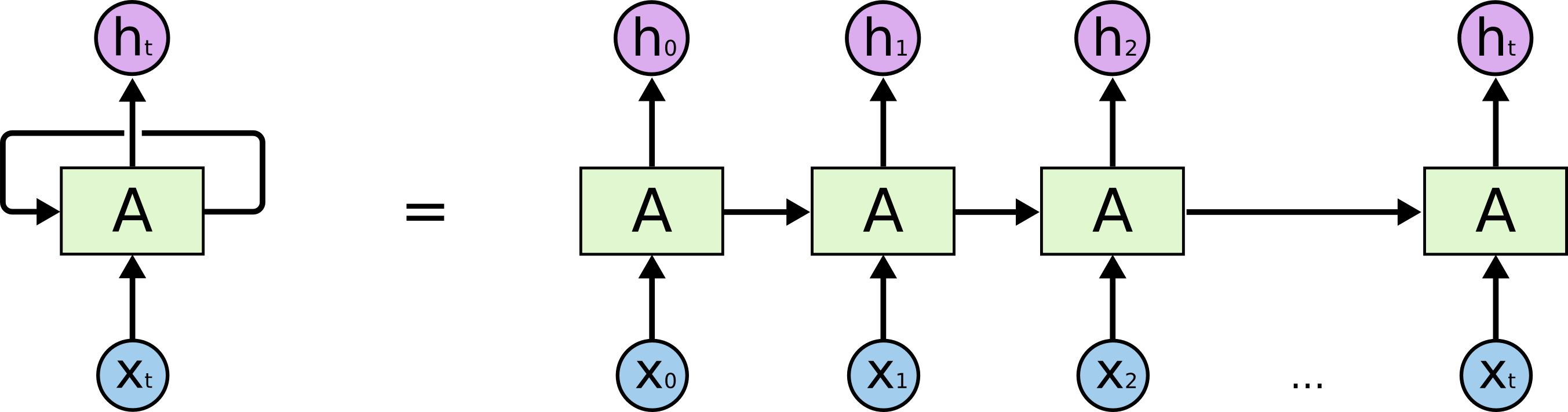
An unrolled recurrent neuron A. Credit: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Not much different than a normal feed-forward network, with one exception: The RNN is able to determine dynamically how deep the network ought to be. In the context of stocks’ historical feature values, consider each vertical formation of x-0 to h-0 a historical snapshot of a state (PE ratio today, PE ratio yesterday, etc…).
Taking The Concept Of RNN One Step Further LSTM (Long/Short Term Memory)
Long Short-Term Memory networks “LSTMs” are a special kind of RNN, capable of learning long-term dependencies. All RNNs have some form of repeating network structure. In a standard RNN the repeating infrastructure is rather straightforward with a single activation function into an output layer of neurons.
In contrast LSTMs contain a more robust infrastructure designed specifically to determine which information ought to be preserved or discarded. Common to LSTM infrastructures is a Cell State layer also called a “conveyor belt”.

A cell state/conveyor belt of the RNN infrastructure, tasked with determining which information should be preserved or discarded.
Instead of having a single neural network layer as in a typical RNN, LSTM holds multiple components, tasked with discriminately adding or removing information to be passed through the “conveyor belt”.
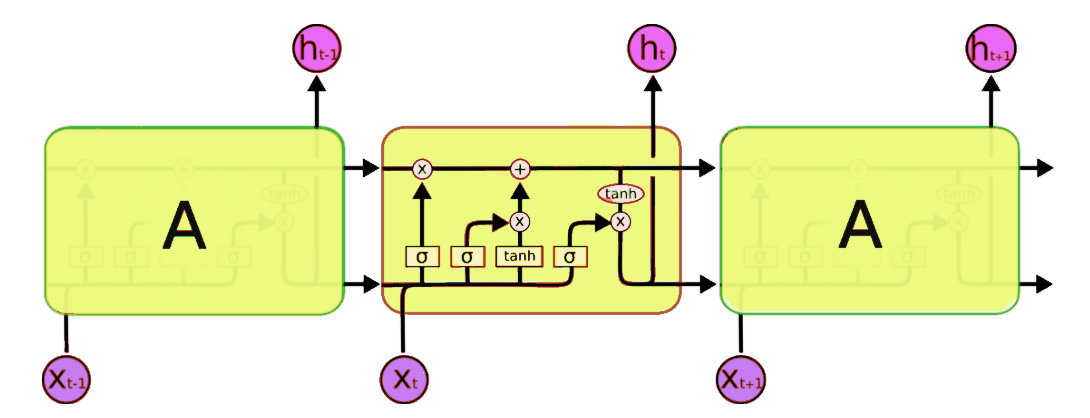
A typical LSTM Cell holding four components tasked with determining which information is discarded, added and outputted to the cell state layer (conveyor belt).
I will not get too deep into the inner structure of an LSTM cell, but it’s important to note that the optionality of letting information flow through is managed by three gates activated by either Sigmoid or tanh functions:
- Forget Gate
- Input Gate
- Output Gate
Under the hood RNNs and LSTMs are not much different than a typical multi-layered neural net. The activation functions force the cell’s outcome to conform to a nonlinear representation, Sigmoid to a value between 0 and 1 and tanh to a value between -1 and 1. This is done mainly to enable the typical deep net’s error-minimization discovery through back propagation and gradient descent.
Key Takeaways about RNNs and Time Series Data:
LSTM cells effectively learn to memorize long-term dependencies and perform well. To the untrained eye, the results may seem somewhat incredible or even magical.
One drawback of RNNs and in particular LSTMs is how taxing they are from a computational resources demand perspective. RNNs can be difficult to train and require deep neural network expertise but are a perfect match for time series data as they can “learn” how to take advantage of sequential signals vs. one time snapshots.
At Lucena we have spent significant efforts on a robust GPUs infrastructure and are extending our AI libraries with new offerings powered by the very same technology. Read about our latest efforts to explore CapsNet and Transformer Architecture.
Want to learn more or ask your specific questions?
Drop a comment below or contact us.


