Erez Katz, CEO and Co-founder of Lucena Research
How Can Machine Learning Validate Alternative Data for Stock Forecasting?
There are many different Machine Learning methods that can be utilized for stock forecasting. A few we recently discussed use neural networks with time series data to:
- – Deploy historical trends into fully connected networks with a wide input layer where input neurons represent data values as point-in-time from present back to some time in history.
- – Transform one-dimensional trends into rich, multi-dimensional image representations. These can then be deployed by CNNs to identify predictions.
- – Utilize RNNs and LSTMs to allow the network to learn and determine what historical data should be stored or discarded for effective stock price-action forecasting.
A few important points to note on stock forecasting:
-
– It’s crucial to distinguish between forecasting the actual price of a stock vs. its direction (higher or lower).
– Even when attempting to forecast the stock’s directional price action, we do it in the context of price action relative to a benchmark.
-
– For example, a stock-price move relative to the S&P 500 (market relative price move). To truly forecast what the price of a stock may be a few days or a few months in the future, the solution would most likely have to be regression-based and deterministic.
-
– That’s a very tall order (and, in my opinion, impossible for high latency investments, the opposite of high frequency investments) given the dynamic and non-stationary nature of the market.
– Our research at Lucena is almost entirely focused on price action classification (whether a stock will be higher relative to its current position). We typically advance our deep learning classifiers with other machine learning deterministic means (mainly Knn, decision trees, etc).
-
– Our research is based on achieving the highest statistical significance. We don’t expect to be right all the time, but rather to be more right than wrong.
-
– This bodes well for deep neural nets based on TensorFlow (an open source deep learning platform and framework, developed by Google Brain) and Keras and Theano (open source component libraries built on top of TenserFlow).
-
-
-
– The networks are trained to minimize loss (the difference between the network outcome and the desired, perfect knowledge, labeled outcome) in order to maximize accuracy and precision.
-
-
-
– For time series data, we advocate daily features that are captured over time but not necessarily daily stock prices. Our research has yielded very little actionable insight from pure stock prices data or for that matter other simple technical features (which are based on price/volume information).
-
-
– The neural networks are trained to assess how various features, captured as daily sentiment scores, trend over time. More importantly, the networks capture how trends of multiple orthogonal data sources when overlaid on top of each other (figuratively speaking) can present more compelling correlations to stocks’ price moves than assessing each feature alone.
-
How effective are deep neural networks in analyzing an alternative data source?
The process of deploying alternative data for price action classification is not only valuable for investors who are looking to deploy strategies. With the rise in alternative data, providers are seeking non-biased researchers to assess and validate their data’s readiness for use in the Financial markets. Read more about how to empirically measure alternative data here.
When you take into account how much data is available to use for stock forecasting it can be a little mind blowing. The buyside can spend countless hours and resources picking and analyzing data only to discover it’s inability to correlate with their specific needs.
Our mission at Lucena has always been to bridge the gap between the data providers and buy side investment professionals. With known data issues such as noise, observations inaccuracies and false news, we’ve had to create enhanced classification technology to be more effective at streamlining the validation process of alternative data.
We pride ourselves on advising our data clients on how to make their data more effective and compelling to the financial consumer. To that end, we will never be a “black box” when it comes to our process so without further delay here is an overview of how we help save our clients time and valuable resources.
De-mything the data validation process
The process of validating an alternative data source can be summed up in the following steps:
- – Ingest raw data
- – Utilize machine learning to:
-
- – Map
- – Feature engineer
- – Backtest for a thorough performance report
- – View paper trading simulation
- – Provide data feed updates
-
- – Deliver to data clients and our buy side clients for use in investment strategies
The process of converting raw data into actionable signals:

The final product is delivered back to our data providers which they can then offer their customers.
Expediting the data validation process: DQE and DME
We’ve created two platforms that expedite the data validation process, a Data Qualification Engine and Data Matching Engine. The two platforms:
-
– Quickly assess the basic maturity of an alternate data source.
-
– Test for data type consistency, universe coverage, sentiment score distribution, survivorship bias, NANs, anomalies and outliers.
-
– Data Map – The process of aggregating (normally to daily time series) and mapping the aggregate score to tradable securities.
-
– Decile breakdown of signal strength to future returns, backtesting and more.
-
– Feature Engineer – Enhance the raw data with additional derived features more suitable to machine learning research. For example: applying time decay, ranking scores against a universe of peers and more.
-
– Event Signal Classification to determine which features work best together for highest future price action consistency.
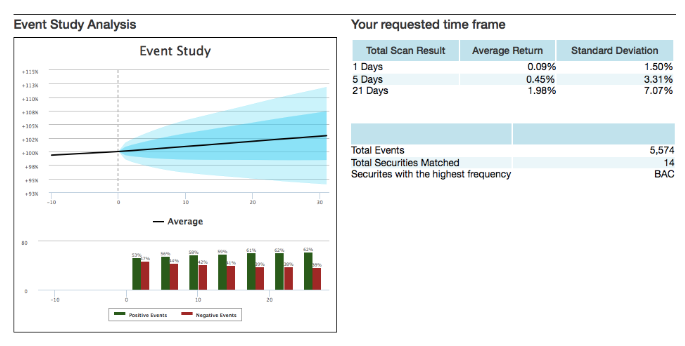
– Backtesting and Paper Trading Simulation – At the conclusion of the validation and enhancement processes, we are ready for backtest simulation of a trading strategy that buys and sells stocks based on the data provider’s signals. Any backtesting can be made a live paper traded portfolio so that the signals to returns correlation is tested perpetually into the future.
- In addition, Lucena provides a comprehensive performance and attribution reporting analysis for a highly visual intuitive assessment.
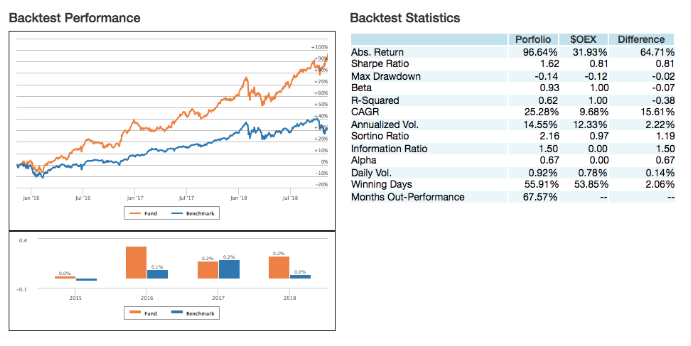
Backtesting simulation of signals strength against a predetermined benchmark. Backtest closely simulates real-life scenario taking into account transactions cost, slippage, and not allowing peeking into the future.
Don’t let data research drain your resources
The explosion of new alternative data brings exciting new dimensionality to deep learning research.
Location data, corporate action data, social media sentiment, consumer spending activity and much more can be used to enhance your investment strategies.
With the rise in Alternative data flooding the market, buy side clients are looking to be smart on how they deploy their research resources. Lucena bridges that gap by allowing an effective automation of sifting substance from noise and allowing the hedge fund managers to concentrate on what’s most promising.
Even the most sophisticated hedge funds are constantly looking for ways to determine if a data provider is worth pursuing. They want to be able to “fail fast” so that precious quant research isn’t wasted on unqualified data. The very same technology we use to deploy predictive signals for investment strategies can be used to assess if an alternative data source contains validated and predictive information.
Interested in learning more about how to extract signals from noise?


