Erez Katz, Lucena Research CEO and Co-founder
During our panel event in NY I shared Lucena’s latest breakthrough in machine learning research using Geoffrey Hinton’s Capsule Networks (CapsNet). Specifically, how we’ve implemented CapsNet to achieve state of the art results. Here I’ll review how a multi-factor ensemble of expert models is geared to anticipate and exploit trend formation of tradable assets. I will also touch on some of the main points that motivated us to explore CapsNet.
Motivations For Using CapsNet
In early 2018, I published several articles and a webinar about applying convolutional neural networks (CNN) to stock forecasting. The idea was to use computer vision in the context of image classification to predict stock price trends.
We wanted to apply machine learning classification techniques that have been proven and used commercially for facial recognition by Facebook or autonomous vehicles by Google. For our purposes, we will train a model to classify images of multiple time series charts overlaid on top of each other.
It is rather intuitive to see the similarities between classifying images of objects (a bird in our example), and classifying images representing multiple time series charts of a stock with an impending price action.
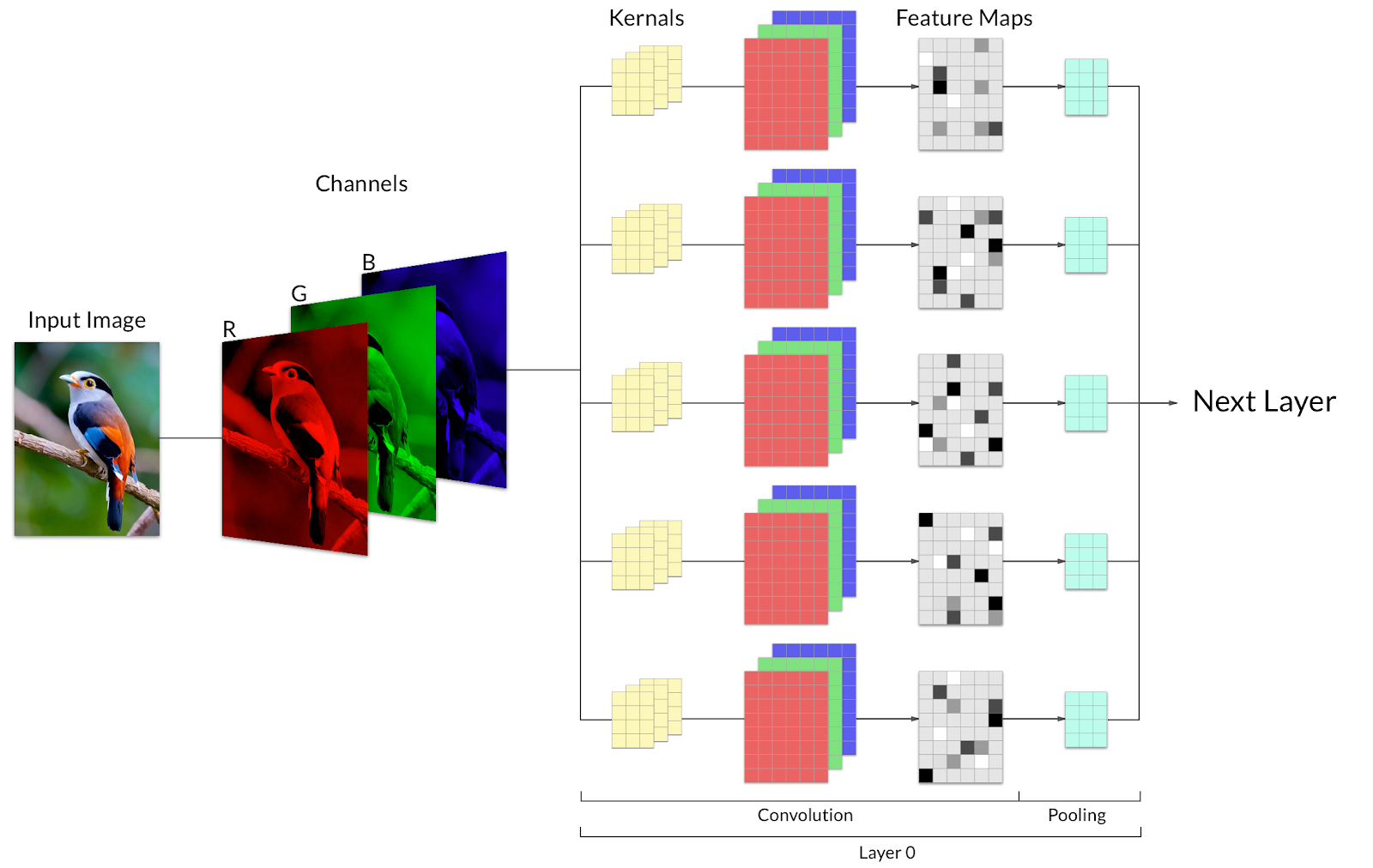
Image 1: A rich colored image of a bird broken down to three channels R,G,B before being fed into the convolutional classifier.
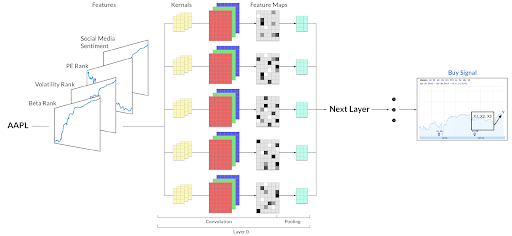
Image 2: A multi-channel representation of time series images before being fed into a CNN for a Buy or Sell classification.
After achieving initial success, we hit a wall. We weren’t able to obtain superior results using the complex and resource-intensive CNN infrastructure versus simpler machine learning infrastructures such as SVM, linear regression, gradient boosting decision trees, etc.
It turns out that in spite of the great success that traditional CNN has enjoyed, it became apparent that it also exhibits major drawbacks. The most detrimental is the information loss when converting a pixelated image into convolutional layers of neurons through Max Pooling.
Max Pooling is the process of downsizing the number of pixels (or neurons) of an image by only keeping the most significant neurons within a cluster and discarding the rest. This process of approximation surprisingly works well for classifying an entire image but falls short when applied to partial-image detection or, in our case, when analyzing time series trends.
Convolutional Neural Network Limitations
Take for example an attempt to detect an image of a bird. The CNN network doesn’t have to store every possible image of a bird but rather learn to approximate sub-objects that together characterize a bird. By detecting objects that resemble a beak, a feather, a tail, etc… the sum of the parts yields a high conviction classification that the image is one of a bird. This process however is extremely flawed commercially for the following reasons:
- Lack of context or sequence preservation between the sub-objects. If the beak is located on the tail, for example, the classifier will still consider the image as one of a bird (although, obviously, no bird carries its beak on its tail).
- Information loss by which meaningful pixels (or neurons) are discarded since max pooling only select one neuron or one pixel from a cluster.
- Vulnerability to adversarial neurons by which changing just a few critical pixels (or neurons) in an image would not change a human’s perspective (the image would still look identical to the naked eye), but could fool the CNN classifier to believe the image is something completely different. Just imagine how devastating it would be if an autonomous vehicle interprets a stop sign as a speed limit sign?
These shortcomings become very apparent when applying CNN to time series trend analysis. The sequence of the ebbs and flows in a time series pattern is essential for distinguishing one pattern from another. This lack of contextual sequencing is further exacerbated when overlaying multiple time series patterns together.
Ultimately, our overarching goal is to consider multiple factors together to project an impending price action of an asset. For example, we could consider how a trend of credit card spending habits, overlaid on top of a trend of social media sentiment, overlaid on top of a technical momentum trend, etc. are used together to yield a highly probable future price movement. Losing the sequence of inflection points in a trend impedes our ability to identify more granular signals within the overall pattern.
Geoffrey Hinton’s Capsule Network To The Rescue
To overcome the above drawbacks, Goeffrey Hinton designed a new version of CNN using “Capsules” to store and train groups of neurons together. This is a stark contrast to traditional CNN which trains individual neurons. With CapsNet, there is no meaningful loss of information through approximation because the neurons are all retained and trained together as a group using descriptive vectors to preserve all the descriptive properties of a sub-objects within an image. For example, a vector can contain size, location, pose, orientation, deformation, texture etc.
Invariance vs. Equivariance
In order to learn how CapsNet learns, we have to understand the distinction between equivariance and invariance. Traditional CNN use filters, or kernels to extract spatial information from an image. Through this process, the same neurons will activate whether an object is detected in the center of an image or anywhere else. This concept is considered “invariant” because there is no distinction between how neurons are activated based on the object’s location, orientation, pose, size etc.
On the other hand, in CapsNet, different neurons will be activated based on the object’s descriptive vector. This allows the network to preserve more information about sub-objects within an image. As objects vary by location, pose or any other descriptive feature, different corresponding neurons within the network will activate accordingly – hence, equivariance.
How do CapsNet Learn?
CapsNet learns by assessing the probability that an object in one layer is associated with another object at a higher layer. The learning occurs as the network tries to combine objects into a single image while traversing through a layered hierarchy of sub-objects, all the way to the top layer in which a complete image reconstruction occurs.
This image reconstruction takes place based on a statistical probability score. Hinton named it “routing by agreement”. Each sub-object capsule determines a probability of its own inclusion in a higher layer capsule. Values are tallied and squashed into a probability score between zero and one. At the top of the routing-by-agreement process, the network tries to reconstruct the original image. The very same traditional backpropagation and gradient descent error minimization are used as the network adjusts the weights of the capsules to minimize marginal error and reconstruction loss. Image reconstruction also serves as a regularizer to avoid overfitting.
Bottom Line
Capsule networks are relatively new and have not quite gained widespread adoption. Nevertheless, it is a fascinating new technology for image classification that has already been used to achieve state of the art results in some domains. The greatest benefit of CapsNet is the fact that the models are trained to detect hierarchical structure of part-to-whole relationships between sub-objects in order to compose a higher-level image. This is perfectly suitable for time series pattern detection.
During my opening remarks on the 26th, I will share both backtests and perpetual trading simulations of portfolios based on CapsNet. Our results are among the most robust and consistent of any research we’ve conducted.
Want to know more about our CapsNet research? Contact Us.


